简单介绍qemu的虚拟化组件的初始化和入口
虚拟化设备分为两类, 一种是全虚拟化 , 一种是半虚拟化 .
一般来说, 全虚拟化设备是指设备相关的实现都在物理机的用户态, 半虚拟化是部分实现在物理机的内核态. 一个常见的半虚拟化标准是virtio设备标准.
但是不同平台的不同虚拟化软件, 对同一个虚拟化设备的实现存在差异, 所以也不一定是按前面的说法去实现的.
传统IO设备 传统的IO设备是全虚拟化设备, 此类设备有IO port及IO memory, 可以通过写IO相关的端口或者内存实现设备交互.
虚拟设备的注册 qemu的每个虚拟化设备都会调用 type_init() 确认设备的注册操作, 调用 type_register/type_register_static 来注册一个虚拟设备, 传入的结构体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct TypeInfo { const char *name; const char *parent; size_t instance_size; size_t instance_align; void (*instance_init)(Object *obj); void (*instance_post_init)(Object *obj); void (*instance_finalize)(Object *obj); bool abstract; size_t class_size; void (*class_init)(ObjectClass *klass, void *data); void (*class_base_init)(ObjectClass *klass, void *data); void *class_data; InterfaceInfo *interfaces; };
以e1000为例的设备注册操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static void e1000_register_types (void ) { int i; type_register_static(&e1000_base_info); for (i = 0 ; i < ARRAY_SIZE(e1000_devices); i++) { const E1000Info *info = &e1000_devices[i]; TypeInfo type_info = {}; type_info.name = info->name; type_info.parent = TYPE_E1000_BASE; type_info.class_data = (void *)info; type_info.class_init = e1000_class_init; type_register(&type_info); } } TypeImpl *type_register_static (const TypeInfo *info) { return type_register(info); } type_init(e1000_register_types)
.name 决定了设备名称, 在qemu中使用 -device 查看所有device的时候可以看到的名字.
.class_init 指示了设备初始化的函数, 这里我关注e1000_class_init的初始化操作.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 static void e1000_class_init (ObjectClass *klass, void *data) { DeviceClass *dc = DEVICE_CLASS(klass); PCIDeviceClass *k = PCI_DEVICE_CLASS(klass); E1000BaseClass *e = E1000_CLASS(klass); const E1000Info *info = data; k->realize = pci_e1000_realize; k->exit = pci_e1000_uninit; k->romfile = "efi-e1000.rom" ; k->vendor_id = PCI_VENDOR_ID_INTEL; k->device_id = info->device_id; k->revision = info->revision; e->phy_id2 = info->phy_id2; k->class_id = PCI_CLASS_NETWORK_ETHERNET; set_bit(DEVICE_CATEGORY_NETWORK, dc->categories); dc->desc = "Intel Gigabit Ethernet" ; dc->reset = qdev_e1000_reset; dc->vmsd = &vmstate_e1000; device_class_set_props(dc, e1000_properties); } struct PCIDeviceClass { DeviceClass parent_class; void (*realize)(PCIDevice *dev, Error **errp); PCIUnregisterFunc *exit ; PCIConfigReadFunc *config_read; PCIConfigWriteFunc *config_write; uint16_t vendor_id; uint16_t device_id; uint8_t revision; uint16_t class_id; uint16_t subsystem_vendor_id; uint16_t subsystem_id; bool is_bridge; const char *romfile; };
k->realize 就是主要的初始化函数. 在realize中, 一般就会初始化对应的IO空间和绑定处理函数.
PCIDeviceClass->config_read和config_write 对应的是设备的PCI 配置空间的读写处理函数.
如果没有声明, 默认在do_pci_register_device中会赋值 pci_default_read_config/pci_default_write_config.
IO handler的初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 static void pci_e1000_realize (PCIDevice *pci_dev, Error **errp) { DeviceState *dev = DEVICE(pci_dev); E1000State *d = E1000(pci_dev); uint8_t *pci_conf; uint8_t *macaddr; pci_dev->config_write = e1000_write_config; pci_conf = pci_dev->config; pci_conf[PCI_CACHE_LINE_SIZE] = 0x10 ; pci_conf[PCI_INTERRUPT_PIN] = 1 ; e1000_mmio_setup(d); pci_register_bar(pci_dev, 0 , PCI_BASE_ADDRESS_SPACE_MEMORY, &d->mmio); pci_register_bar(pci_dev, 1 , PCI_BASE_ADDRESS_SPACE_IO, &d->io); ... } static void e1000_mmio_setup (E1000State *d) { int i; const uint32_t excluded_regs[] = { E1000_MDIC, E1000_ICR, E1000_ICS, E1000_IMS, E1000_IMC, E1000_TCTL, E1000_TDT, PNPMMIO_SIZE }; memory_region_init_io(&d->mmio, OBJECT(d), &e1000_mmio_ops, d, "e1000-mmio" , PNPMMIO_SIZE); memory_region_add_coalescing(&d->mmio, 0 , excluded_regs[0 ]); for (i = 0 ; excluded_regs[i] != PNPMMIO_SIZE; i++) memory_region_add_coalescing(&d->mmio, excluded_regs[i] + 4 , excluded_regs[i+1 ] - excluded_regs[i] - 4 ); memory_region_init_io(&d->io, OBJECT(d), &e1000_io_ops, d, "e1000-io" , IOPORT_SIZE); } void memory_region_init_io (MemoryRegion *mr, Object *owner, const MemoryRegionOps *ops, void *opaque, const char *name, uint64_t size) { memory_region_init(mr, owner, name, size); mr->ops = ops ? ops : &unassigned_mem_ops; mr->opaque = opaque; mr->terminates = true ; } static const MemoryRegionOps e1000_mmio_ops = { .read = e1000_mmio_read, .write = e1000_mmio_write, .endianness = DEVICE_LITTLE_ENDIAN, .impl = { .min_access_size = 4 , .max_access_size = 4 , }, }; static const MemoryRegionOps e1000_io_ops = { .read = e1000_io_read, .write = e1000_io_write, .endianness = DEVICE_LITTLE_ENDIAN, };
注意, 此处的pci_dev->config_write = e1000_write_config; 是PCIDevice结构体, realize函数由 pci_qdev_realize 调取, 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 static void pci_qdev_realize (DeviceState *qdev, Error **errp) { PCIDevice *pci_dev = (PCIDevice *)qdev; PCIDeviceClass *pc = PCI_DEVICE_GET_CLASS(pci_dev); ... pci_dev = do_pci_register_device(pci_dev, object_get_typename(OBJECT(qdev)), pci_dev->devfn, errp); if (pci_dev == NULL ) return ; if (pc->realize) { pc->realize(pci_dev, &local_err); } ... } static PCIDevice *do_pci_register_device (PCIDevice *pci_dev, const char *name, int devfn, Error **errp) { PCIDeviceClass *pc = PCI_DEVICE_GET_CLASS(pci_dev); PCIConfigReadFunc *config_read = pc->config_read; PCIConfigWriteFunc *config_write = pc->config_write; ... if (!config_read) config_read = pci_default_read_config; if (!config_write) config_write = pci_default_write_config; pci_dev->config_read = config_read; pci_dev->config_write = config_write; }
从顺序可以看到, realize函数在 do_pci_register_device 之后, do_pci_register_device 也会把 PCIDeviceClass->config_write 赋值给 PCIDevice->config_write. 所以最终的config_write是什么函数, 以realize为准.
e1000刚好既有IO port 又有 IO memory.
从代码可以看出, 他们的初始化大同小异. 最开始会调用 memory_region_init 初始化MemoryRegion, 之后将对应的 MemoryRegion 绑定ops. 这里, port 绑定的 e1000_io_ops, memory 绑定的e1000_mmio_ops.
memory_region_init_io 只是memory_region_init 的一个封装.
在初始化好 MemoryRegion 后, 会调用 pci_register_bar 注册它. 如下示例:
1 2 pci_register_bar(pci_dev, 0 , PCI_BASE_ADDRESS_SPACE_MEMORY, &d->mmio); pci_register_bar(pci_dev, 1 , PCI_BASE_ADDRESS_SPACE_IO, &d->io);
第二个参数表面了注册到PCI 配置空间的哪个bar里(参考后续的pci配置空间). 第三个参数指示该 MemoryRegion的类型是port 还是memory.
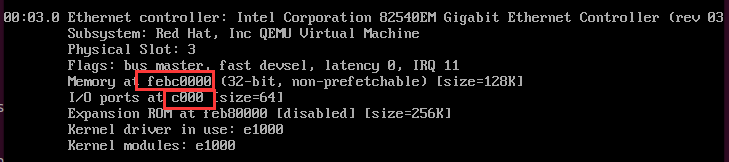
至于具体的IO port或者memory的值是多少, 取决于Guest的操作系统怎么配置PCI配置空间的. 我们可以通过 lspci -v来查看相关配置:
特殊的IO port handler 除了上述的常规注册MemoryRegionOps操作外, 还有一种注册IO handler的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 void portio_list_init (PortioList *piolist, Object *owner, const MemoryRegionPortio *callbacks, void *opaque, const char *name) { unsigned n = 0 ; while (callbacks[n].size) { ++n; } piolist->ports = callbacks; piolist->nr = 0 ; piolist->regions = g_new0(MemoryRegion *, n); piolist->address_space = NULL ; piolist->opaque = opaque; piolist->owner = owner; piolist->name = name; piolist->flush_coalesced_mmio = false ; } static const MemoryRegionOps portio_ops = { .read = portio_read, .write = portio_write, .endianness = DEVICE_LITTLE_ENDIAN, .valid.unaligned = true , .impl.unaligned = true , }; static void portio_list_add_1 (PortioList *piolist, const MemoryRegionPortio *pio_init, unsigned count, unsigned start, unsigned off_low, unsigned off_high) { MemoryRegionPortioList *mrpio; unsigned i; mrpio = g_malloc0(sizeof (MemoryRegionPortioList) + sizeof (MemoryRegionPortio) * (count + 1 )); mrpio->portio_opaque = piolist->opaque; memcpy (mrpio->ports, pio_init, sizeof (MemoryRegionPortio) * count); memset (mrpio->ports + count, 0 , sizeof (MemoryRegionPortio)); for (i = 0 ; i < count; ++i) { mrpio->ports[i].offset -= off_low; mrpio->ports[i].base = start + off_low; } memory_region_init_io(&mrpio->mr, piolist->owner, &portio_ops, mrpio, piolist->name, off_high - off_low); if (piolist->flush_coalesced_mmio) { memory_region_set_flush_coalesced(&mrpio->mr); } memory_region_add_subregion(piolist->address_space, start + off_low, &mrpio->mr); piolist->regions[piolist->nr] = &mrpio->mr; ++piolist->nr; } void portio_list_add (PortioList *piolist, MemoryRegion *address_space, uint32_t start) { const MemoryRegionPortio *pio, *pio_start = piolist->ports; unsigned int off_low, off_high, off_last, count; piolist->address_space = address_space; off_last = off_low = pio_start->offset; off_high = off_low + pio_start->len + pio_start->size - 1 ; count = 1 ; for (pio = pio_start + 1 ; pio->size != 0 ; pio++, count++) { assert(pio->offset >= off_last); off_last = pio->offset; if (off_last > off_high) { portio_list_add_1(piolist, pio_start, count, start, off_low, off_high); pio_start = pio; off_low = off_last; off_high = off_low + pio->len + pio_start->size - 1 ; count = 0 ; } else if (off_last + pio->len > off_high) { off_high = off_last + pio->len + pio_start->size - 1 ; } } portio_list_add_1(piolist, pio_start, count, start, off_low, off_high); }
这种特殊的io port的handler是在行51注册的 portio_ops 来处理的, 即portio_read 和portio_write.
之后, portio_write函数通过遍历注册的port, 来调用对应的处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 static const MemoryRegionPortio *find_portio (MemoryRegionPortioList *mrpio, uint64_t offset, unsigned size, bool write) { const MemoryRegionPortio *mrp; for (mrp = mrpio->ports; mrp->size; ++mrp) { if (offset >= mrp->offset && offset < mrp->offset + mrp->len && size == mrp->size && (write ? (bool )mrp->write : (bool )mrp->read)) { return mrp; } } return NULL ; } static uint64_t portio_read (void *opaque, hwaddr addr, unsigned size) { MemoryRegionPortioList *mrpio = opaque; const MemoryRegionPortio *mrp = find_portio(mrpio, addr, size, false ); uint64_t data; data = ((uint64_t )1 << (size * 8 )) - 1 ; if (mrp) { data = mrp->read(mrpio->portio_opaque, mrp->base + addr); } else if (size == 2 ) { mrp = find_portio(mrpio, addr, 1 , false ); if (mrp) { data = mrp->read(mrpio->portio_opaque, mrp->base + addr); if (addr + 1 < mrp->offset + mrp->len) { data |= mrp->read(mrpio->portio_opaque, mrp->base + addr + 1 ) << 8 ; } else { data |= 0xff00 ; } } } return data; } static void portio_write (void *opaque, hwaddr addr, uint64_t data, unsigned size) { MemoryRegionPortioList *mrpio = opaque; const MemoryRegionPortio *mrp = find_portio(mrpio, addr, size, true ); if (mrp) { mrp->write(mrpio->portio_opaque, mrp->base + addr, data); } else if (size == 2 ) { mrp = find_portio(mrpio, addr, 1 , true ); if (mrp) { mrp->write(mrpio->portio_opaque, mrp->base + addr, data & 0xff ); if (addr + 1 < mrp->offset + mrp->len) { mrp->write(mrpio->portio_opaque, mrp->base + addr + 1 , data >> 8 ); } } } }
举例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 static const MemoryRegionPortio vbe_portio_list[] = { { 0 , 1 , 2 , .read = vbe_ioport_read_index, .write = vbe_ioport_write_index }, # ifdef TARGET_I386 { 1 , 1 , 2 , .read = vbe_ioport_read_data, .write = vbe_ioport_write_data }, # endif { 2 , 1 , 2 , .read = vbe_ioport_read_data, .write = vbe_ioport_write_data }, PORTIO_END_OF_LIST(), }; void vga_init (VGACommonState *s, Object *obj, MemoryRegion *address_space, MemoryRegion *address_space_io, bool init_vga_ports) { MemoryRegion *vga_io_memory; const MemoryRegionPortio *vga_ports, *vbe_ports; qemu_register_reset(vga_reset, s); s->bank_offset = 0 ; s->legacy_address_space = address_space; vga_io_memory = vga_init_io(s, obj, &vga_ports, &vbe_ports); memory_region_add_subregion_overlap(address_space, 0x000a0000 , vga_io_memory, 1 ); memory_region_set_coalescing(vga_io_memory); if (init_vga_ports) { portio_list_init(&s->vga_port_list, obj, vga_ports, s, "vga" ); portio_list_set_flush_coalesced(&s->vga_port_list); portio_list_add(&s->vga_port_list, address_space_io, 0x3b0 ); } if (vbe_ports) { portio_list_init(&s->vbe_port_list, obj, vbe_ports, s, "vbe" ); portio_list_add(&s->vbe_port_list, address_space_io, 0x1ce ); } }
最终, 当读 0x1ce 端口的时候, 就会调用vbe_ioport_read_index函数.
其实在vmware workstation里也可以看到类似的影子, 比如访问vmci设备的时候, 也是有个封装的上层处理函数在分发.
PCI 配置空间 这里简要介绍下PCI配置空间. 当一个设备加入的时候, 设备管理器要了解这个设备是干什么的, 怎么交互, 就需要读取设备的PCI配置空间. 它结构如下:
Vendor ID :厂商ID。知名的设备厂商的ID。FFFFh是一个非法厂商ID,可它来判断PCI设备是否存在。
Device ID :设备ID。某厂商生产的设备的ID。操作系统就是凭着 Vendor ID和Device ID 找到对应驱动程序的。
Class Code :类代码。共三字节,分别是 类代码、子类代码、编程接口。类代码不仅用于区分设备类型,还是编程接口的规范,这就是为什么会有通用驱动程序。
IRQ Line :IRQ编号。PC机以前是靠两片8259芯片来管理16个硬件中断。现在为了支持对称多处理器,有了APIC(高级可编程中断控制器),它支持管理24个中断。
IRQ Pin :中断引脚。PCI有4个中断引脚,该寄存器表明该设备连接的是哪个引脚。
Bars : 一个有6个bar, 具体的使用看设备本身的实现. 当虚拟机识别到它的时候, 会向该区域写入值, 指示设备的bar用哪部分端口或内存地址.
如何访问配置空间呢?可通过访问0xCF8h、0xCFCh 端口来实现。
下面的代码示例了通过遍历所有的bus/dev/func组合来搜索特定的vid和did的设备的bars.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #define PCI_CONFIG_ADDRESS 0xcf8 #define PCI_CONFIG_DATA 0xcfc #define PCI_BASE_ADDRESS_MEM_MASK (~0x0fUL) u32 retrieveAddress (u32 vid, u32 did, u32 *bars) { u32 bus, dev, func; u32 dwAddr, dwData; int i; for (bus = 0 ; bus <= 255 ; bus++) { for (dev = 0 ; dev < 32 ; dev++) { for (func = 0 ; func < 8 ; func++) { dwAddr = 0x80000000 + (bus << 16 ) + (dev << 11 ) + (func << 8 ); outl(dwAddr, PCI_CONFIG_ADDRESS); dwData = inl(PCI_CONFIG_DATA); if ((dwData & 0xffff ) == vid){ if (((dwData >> 16 ) & 0xffff ) == did) { for (i = 0 ; i < 6 ; i++) { outl(dwAddr | (0x10 + i * 4 ), PCI_CONFIG_ADDRESS); dwData = inl(PCI_CONFIG_DATA); if (dwData & 1 ) { dwData ^= 1 ; } else { dwData &= PCI_BASE_ADDRESS_MEM_MASK; } bars[i] = dwData; } return dwAddr; } } } } } return 0 ; }
对于一些现代PCIe设备, 配置空间更大, 就需要使用mmconfig来获取相应的配置信息.
可以参考PCI配置空间
半虚拟化设备Virtio virtio设备分类两种, 一种是legacy, 一种是modern.
legacy的, 就通过IO port 管理它的配置, modern就通过IO memory 来管理它的配置
要了解virtio设备, 还需要了解它的IO配置接口.
当一个virtio设备开始加载的时候, 会调用 virtio_pci_device_plugged 去初始化它的PCI/PCIe 的 IO 空间.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 static void virtio_pci_device_plugged (DeviceState *d, Error **errp) { ...; if (modern) { virtio_pci_modern_regions_init(proxy, vdev->name); virtio_pci_modern_mem_region_map(proxy, &proxy->common, &cap); virtio_pci_modern_mem_region_map(proxy, &proxy->isr, &cap); virtio_pci_modern_mem_region_map(proxy, &proxy->device, &cap); virtio_pci_modern_mem_region_map(proxy, &proxy->notify, ¬ify.cap); pci_register_bar(&proxy->pci_dev, proxy->modern_mem_bar_idx, PCI_BASE_ADDRESS_SPACE_MEMORY | PCI_BASE_ADDRESS_MEM_PREFETCH | PCI_BASE_ADDRESS_MEM_TYPE_64, &proxy->modern_bar); ... } if (legacy) { size = VIRTIO_PCI_REGION_SIZE(&proxy->pci_dev) + virtio_bus_get_vdev_config_len(bus); size = pow2ceil(size); memory_region_init_io(&proxy->bar, OBJECT(proxy), &virtio_pci_config_ops, proxy, "virtio-pci" , size); pci_register_bar(&proxy->pci_dev, proxy->legacy_io_bar_idx, PCI_BASE_ADDRESS_SPACE_IO, &proxy->bar); } } static const MemoryRegionOps virtio_pci_config_ops = { .read = virtio_pci_config_read, .write = virtio_pci_config_write, .impl = { .min_access_size = 1 , .max_access_size = 4 , }, .endianness = DEVICE_LITTLE_ENDIAN, }; static void virtio_pci_modern_regions_init (VirtIOPCIProxy *proxy, const char *vdev_name) { static const MemoryRegionOps common_ops = { .read = virtio_pci_common_read, .write = virtio_pci_common_write, .impl = { .min_access_size = 1 , .max_access_size = 4 , }, .endianness = DEVICE_LITTLE_ENDIAN, }; static const MemoryRegionOps isr_ops = { .read = virtio_pci_isr_read, .write = virtio_pci_isr_write, .impl = { .min_access_size = 1 , .max_access_size = 4 , }, .endianness = DEVICE_LITTLE_ENDIAN, }; static const MemoryRegionOps device_ops = { .read = virtio_pci_device_read, .write = virtio_pci_device_write, .impl = { .min_access_size = 1 , .max_access_size = 4 , }, .endianness = DEVICE_LITTLE_ENDIAN, }; static const MemoryRegionOps notify_ops = { .read = virtio_pci_notify_read, .write = virtio_pci_notify_write, .impl = { .min_access_size = 1 , .max_access_size = 4 , }, .endianness = DEVICE_LITTLE_ENDIAN, }; static const MemoryRegionOps notify_pio_ops = { .read = virtio_pci_notify_read, .write = virtio_pci_notify_write_pio, .impl = { .min_access_size = 1 , .max_access_size = 4 , }, .endianness = DEVICE_LITTLE_ENDIAN, }; g_autoptr(GString) name = g_string_new(NULL ); g_string_printf(name, "virtio-pci-common-%s" , vdev_name); memory_region_init_io(&proxy->common.mr, OBJECT(proxy), &common_ops, proxy, name->str, proxy->common.size); g_string_printf(name, "virtio-pci-isr-%s" , vdev_name); memory_region_init_io(&proxy->isr.mr, OBJECT(proxy), &isr_ops, proxy, name->str, proxy->isr.size); g_string_printf(name, "virtio-pci-device-%s" , vdev_name); memory_region_init_io(&proxy->device.mr, OBJECT(proxy), &device_ops, proxy, name->str, proxy->device.size); g_string_printf(name, "virtio-pci-notify-%s" , vdev_name); memory_region_init_io(&proxy->notify.mr, OBJECT(proxy), ¬ify_ops, proxy, name->str, proxy->notify.size); g_string_printf(name, "virtio-pci-notify-pio-%s" , vdev_name); memory_region_init_io(&proxy->notify_pio.mr, OBJECT(proxy), ¬ify_pio_ops, proxy, name->str, proxy->notify_pio.size); } static void virtio_pci_modern_mem_region_map (VirtIOPCIProxy *proxy, VirtIOPCIRegion *region, struct virtio_pci_cap *cap) { virtio_pci_modern_region_map(proxy, region, cap, &proxy->modern_bar, proxy->modern_mem_bar_idx); } static void virtio_pci_modern_region_map (VirtIOPCIProxy *proxy, VirtIOPCIRegion *region, struct virtio_pci_cap *cap, MemoryRegion *mr, uint8_t bar) { memory_region_add_subregion(mr, region->offset, ®ion->mr); cap->cfg_type = region->type; cap->bar = bar; cap->offset = cpu_to_le32(region->offset); cap->length = cpu_to_le32(region->size); virtio_pci_add_mem_cap(proxy, cap); }
上面可以明显看到, 如果是modern 类型, 就会调用 virtio_pci_modern_regions_init 注册很多个MemoryRegion, 之后调用 virtio_pci_modern_mem_region_map 重新映射到 proxy->modern_bar 这个region里, 之后是如下的调用
1 2 3 4 5 pci_register_bar(&proxy->pci_dev, proxy->modern_mem_bar_idx, PCI_BASE_ADDRESS_SPACE_MEMORY | PCI_BASE_ADDRESS_MEM_PREFETCH | PCI_BASE_ADDRESS_MEM_TYPE_64, &proxy->modern_bar);
把 modern_bar 注册为IO memory.
而如果是legacy 类型, 只是注册了一个IO port. 如下所示:
1 2 pci_register_bar(&proxy->pci_dev, proxy->legacy_io_bar_idx, PCI_BASE_ADDRESS_SPACE_IO, &proxy->bar);
通过访问这些IO, 就可以管理virtio设备.
Virtio设备的注册 在qemu中, virtio设备需要挂载在virtio-pci上. 一般来说, virtio设备的特点在于它大部分的实现都在内核, 用户态只需要配置基础的信息即可. 但是qemu本身也实现了一些相关设备的用户态实现, 比如virtio-net, 当启用vhost的时候, 它用户态基本上不做什么操作, 当未启用vhost时, 它的实现就在用户态的virtio-net.c文件中.
virtio设备主要关注的是它的VirtQueue的注册.
以 virtio-net 未启用vhost的情况举例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 static void virtio_net_device_realize (DeviceState *dev, Error **errp) { ... for (i = 0 ; i < n->max_queue_pairs; i++) { virtio_net_add_queue(n, i); } n->ctrl_vq = virtio_add_queue(vdev, 64 , virtio_net_handle_ctrl); } static void virtio_net_add_queue (VirtIONet *n, int index) { VirtIODevice *vdev = VIRTIO_DEVICE(n); n->vqs[index].rx_vq = virtio_add_queue(vdev, n->net_conf.rx_queue_size, virtio_net_handle_rx); if (n->net_conf.tx && !strcmp (n->net_conf.tx, "timer" )) { n->vqs[index].tx_vq = virtio_add_queue(vdev, n->net_conf.tx_queue_size, virtio_net_handle_tx_timer); n->vqs[index].tx_timer = timer_new_ns(QEMU_CLOCK_VIRTUAL, virtio_net_tx_timer, &n->vqs[index]); } else { n->vqs[index].tx_vq = virtio_add_queue(vdev, n->net_conf.tx_queue_size, virtio_net_handle_tx_bh); n->vqs[index].tx_bh = qemu_bh_new(virtio_net_tx_bh, &n->vqs[index]); } n->vqs[index].tx_waiting = 0 ; n->vqs[index].n = n; } VirtQueue *virtio_add_queue (VirtIODevice *vdev, int queue_size, VirtIOHandleOutput handle_output) { int i; for (i = 0 ; i < VIRTIO_QUEUE_MAX; i++) { if (vdev->vq[i].vring.num == 0 ) break ; } if (i == VIRTIO_QUEUE_MAX || queue_size > VIRTQUEUE_MAX_SIZE) abort (); vdev->vq[i].vring.num = queue_size; vdev->vq[i].vring.num_default = queue_size; vdev->vq[i].vring.align = VIRTIO_PCI_VRING_ALIGN; vdev->vq[i].handle_output = handle_output; vdev->vq[i].handle_aio_output = NULL ; vdev->vq[i].used_elems = g_malloc0(sizeof (VirtQueueElement) * queue_size); return &vdev->vq[i]; }
重点关注 virtio_add_queue 函数的调用即可. 它用来向virtio-pci注册每个queue对应的处理函数. 比如n->ctrl_vq = virtio_add_queue(vdev, 64, virtio_net_handle_ctrl); 就是注册了size为64的VirtQueue, 对ctrl_vq的访问都会触发 virtio_net_handle_ctrl 函数调用.
virtio设备的访问 以virtio-net设备为例, 假设注册的是legacy类型, 那么通过访问它的port, 就可以调用到virtio-pci的 virtio_pci_config_write->virtio_ioport_write 函数.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static void virtio_ioport_write (void *opaque, uint32_t addr, uint32_t val) { VirtIOPCIProxy *proxy = opaque; VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus); hwaddr pa; switch (addr) { case VIRTIO_PCI_GUEST_FEATURES: if (val & (1 << VIRTIO_F_BAD_FEATURE)) { val = virtio_bus_get_vdev_bad_features(&proxy->bus); } virtio_set_features(vdev, val); break ; case VIRTIO_PCI_QUEUE_SEL: if (val < VIRTIO_QUEUE_MAX) vdev->queue_sel = val; break ; case VIRTIO_PCI_QUEUE_NOTIFY: if (val < VIRTIO_QUEUE_MAX) { virtio_queue_notify(vdev, val); } break ; ... } }
假设case是 VIRTIO_PCI_QUEUE_NOTIFY
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void virtio_queue_notify (VirtIODevice *vdev, int n) { VirtQueue *vq = &vdev->vq[n]; if (unlikely(!vq->vring.desc || vdev->broken)) { return ; } trace_virtio_queue_notify(vdev, vq - vdev->vq, vq); if (vq->host_notifier_enabled) { event_notifier_set(&vq->host_notifier); } else if (vq->handle_output) { vq->handle_output(vdev, vq); if (unlikely(vdev->start_on_kick)) { virtio_set_started(vdev, true ); } } }
从上面可以看到, 它实际是通过vdev->vq来获取相关的VirtQueue的, 而上面virtio-net初始化的时候, max_queue_pairs是1, 所以它最终只初始化了3个queue. 按照初始化时调用virtio_add_queue的顺序, vq[0]就是rx_vq, vq[1]是tx_vq, vq[2]是ctrl_vq. 所以如果n是0, 最后调用的vq->handle_output 就会是 virtio_net_handle_rx 函数.